Consider this fact: there are whole sections of the Internet that you will never see even once throughout your lifetime. The Internet is simply too large for any one given person to fully explore. The average Internet user like you probably hasn’t, and never will, come across things like Japanese toilet reviews (amazing inventions by the way), or tutorials to ‘core-boot’ old ThinkPad laptops to avoid the NSA, or the amazing motion picture Goncharov. Even if you have, probably not all three.
“What If” videos almost became one of those for me.
What Are “What If” Videos?
These videos follow a common recipe: A narrator, given a fandom (usually anime ones like My Hero Academia and Naruto), explores an alternative timeline where something is different. Maybe the main character has extra powers, maybe a key plot point goes differently. They then go on and make up a whole new story, detailing the conflicts and romance between characters, much like an ordinary fanfic.
Except, they are fanfics. Actual fanfics, pulled off AO3, FFN and Wattpad, given a different title, with random thumbnail and background images added to them, narrated by computer text-to-speech synthesizers.
They are very easy to make: pick a fanfic, copy all the text into a text-to-speech generator, mix the resulting audio file with some generic art from the fandom as the background, give it a snappy title like “What if Deku had the Power of Ten Rings”, photoshop an attention-grabbing thumbnail, dump it onto YouTube and get thousands of views.
In fact, the process is so straightforward and requires so little effort, it’s pretty clear some of these channels have automated pipelines to pump these out en-masse. They don’t bother with asking the fic authors for permission. Sometimes they don’t even bother with putting the fic’s link in the description or crediting the author. These content-farms then monetise these videos, so they get a cut from YouTube’s ads.
From what I can see, in the past two years these channels have formed a whole industry around this concept, with more than 700 videos under the hashtag #animewhatif, and a simple search for specific fandoms yields hundreds more. And because this is such an obscure corner of the Internet, most fanfic authors never even realise this is happening.
In short, an industry has emerged from the systematic copyright theft of fanfiction, for profit.
Project Copy-Knight
Since the adversaries almost certainly have automated systems set up for this, the only realistic countermeasure is with another automated system. Identifying fanfics manually by listening to the videos and searching them up with tags is just too slow and impractical.
And so, I came up with a simple automated pipeline to identify the original authors of “What If” videos.
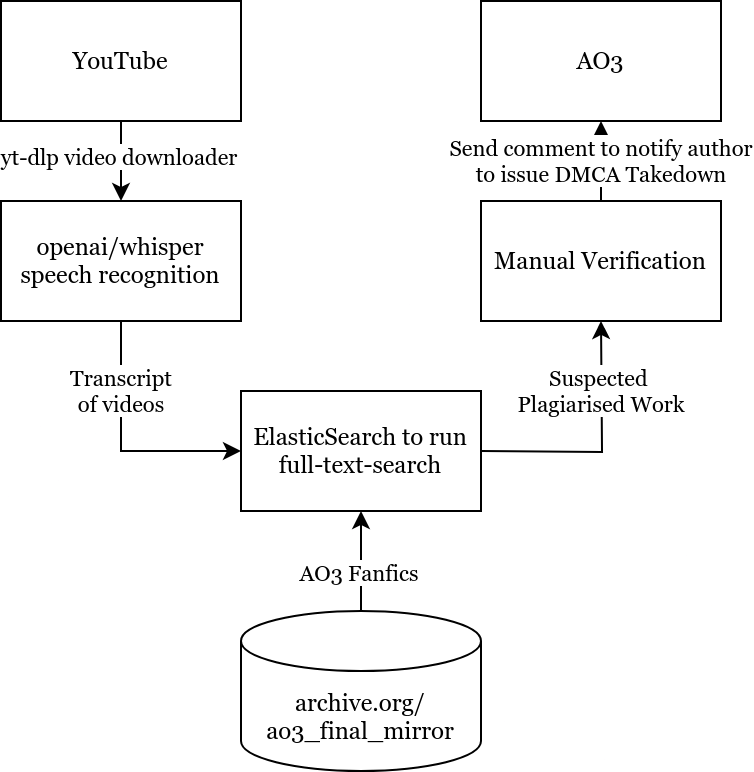
It would go download these videos, run speech recognition on it, search the text through a database full of AO3 fics, and identify which work it came from. After manual confirmation, the original authors will be notified that their works have been subject to copyright theft, and instructions provided on how to DMCA-strike the channel out of existence.
I built a prototype over the weekend, and it works surprisingly well:
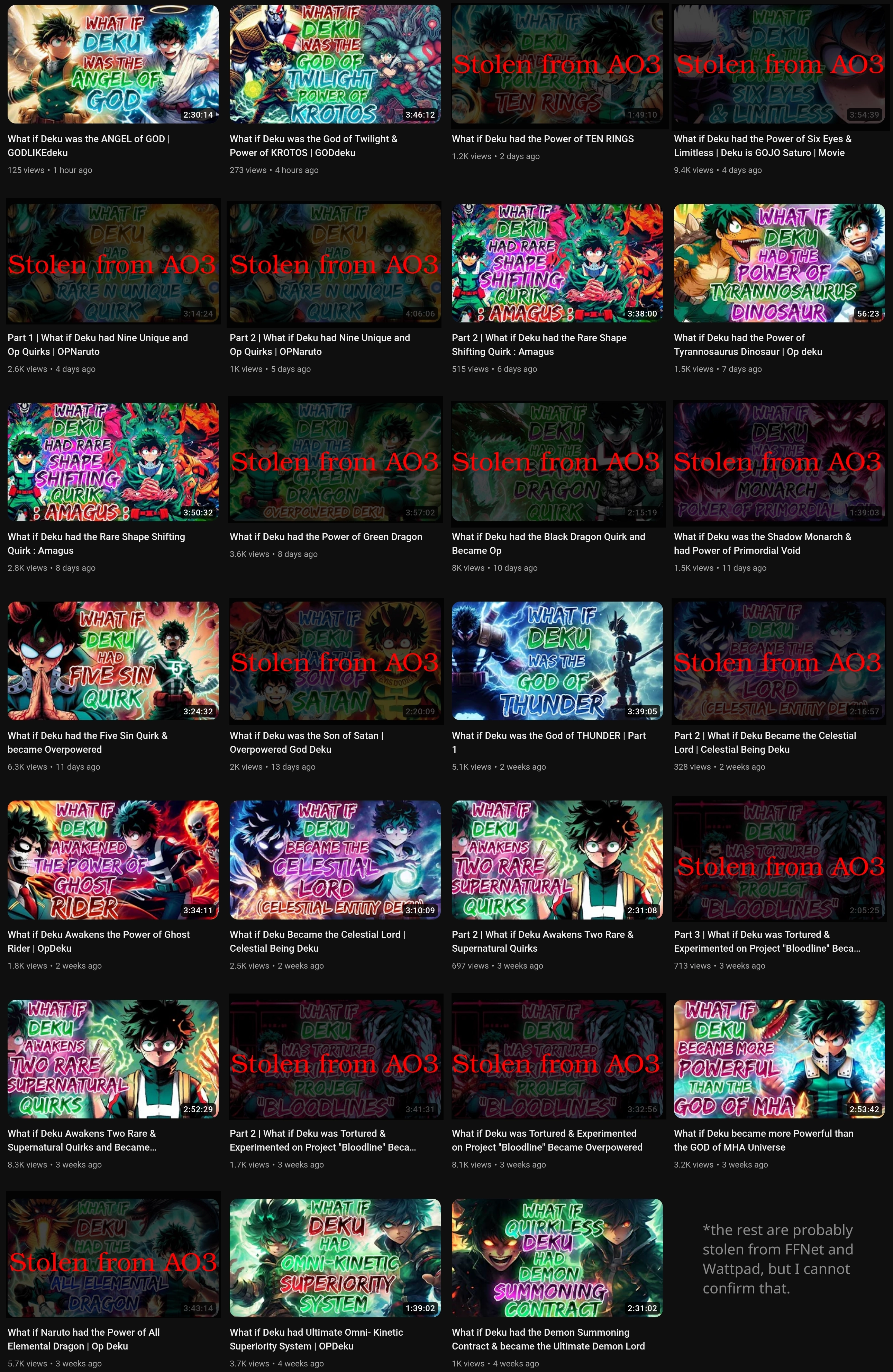
On a randomly-selected YouTube channel (in this case Infinite Paradox Fanfic), the toolchain was able to identify the origin of half of the content. The raw output, after manual verification, turned out to be extremely accurate. The time taken to identify the source of a video was about 5 minutes, most of those were spent running Whisper, and the actual full-text-search query and Levenshtein analysis was less than 5 seconds.
The other videos probably came from fanfiction websites other than AO3, like fanfiction.net or Wattpad. As I do not have access to archives of those websites, I cannot identify the other ones, but they are almost certainly not original.
Armed with this fantastic proof-of-concept, I’m officially declaring war against “What If” videos. The mission statement of Project Copy-Knight will be the elimination of “What If” videos based on the theft of AO3 content on YouTube.
I Need Your Help
I am acutely aware that I cannot accomplish this on my own. There are many moving parts in this system that simply cannot be completely automated – like the selection of YouTube channels to feed into the toolchain, the manual verification step to prevent false-positives being sent to authors, the reaching-out to authors who have comments disabled, etc, etc.
So, if you are interested in helping to defend fanworks, or just want to have a chat or ask about the technical details of the toolchain, please consider joining my Discord server. I could really use your help.
Acknowledgements
I am very thankful of the following projects and people, without which this project would have been completely impossible.
Listed in order of use in the toolchain:
- yt-dlp, for enabling the mass download of videos from YouTube;
- openai/whisper, for enabling the generation of video transcripts locally (notably, this is probably one of the few instances where a project by OpenAI actually helped to advance the protection of copyright);
- Internet Archive, for hosting a mirror repository of AO3 fanfics;
- AO3_final_mirror, for crawling the entirety of AO3 and putting it up on Internet Archive for all to use. Special thanks goes to @Entropy11235813 for doing God’s work for us all;
- Apache Lucene, for powering the full-text-search functionality in ElasticSearch and other similar search engines like Solr and OpenSearch;
- And a final very special thank-you to u/Emma_Iveli for making this post on Reddit – without this post I would have never found this corner of the Internet, and would not have had access to the ground-truth reference of a corresponding pair of video and fanfic, which was indispensible in the feasibility study phase of the project and later calibration of the system for large-scale use.
Comments
Please leave your comments on the post below.
